Web scraping z WebHarvy - Konfiguracja serwerów proxy Stableproxy
Opublikowany
лип. 27-е, 2024
Temat
podręcznik
Czas czytania
10 min


Autor
StableProxy
Czym jest WebHarvy?
WebHarvy to potężne narzędzie do zbierania danych, które posiada funkcje ułatwiające wyodrębnianie tekstu, HTML i obrazów ze stron internetowych, oszczędzając Twój czas i zasoby. WebHarvy umożliwia łatwe logowanie, wypełnianie formularzy i nawigację po skomplikowanych stronach internetowych. Co więcej, serwery proxy łatwo integrują się z WebHarvy, co pozwala na rozszerzenie możliwości pracy ze stronami internetowymi.
Wzmocnij swoje umiejętności web scraping, integrując serwery proxy Stableproxy z WebHarvy!
Jeśli jesteś gotowy do ulepszenia swoich umiejętności zbierania danych z sieci, integracja Stableproxy z WebHarvy będzie doskonałym rozwiązaniem. Wsparcie dla serwerów proxy zapewnia bardziej efektywne i efektywne zbieranie publicznych danych. Aby rozpocząć pracę, wykonaj następujące kroki:
- Pobierz i zainstaluj aplikację WebHarvy ze strony webharvy.com.
- Po zainstalowaniu WebHarvy otwórz zakładkę "Ustawienia".
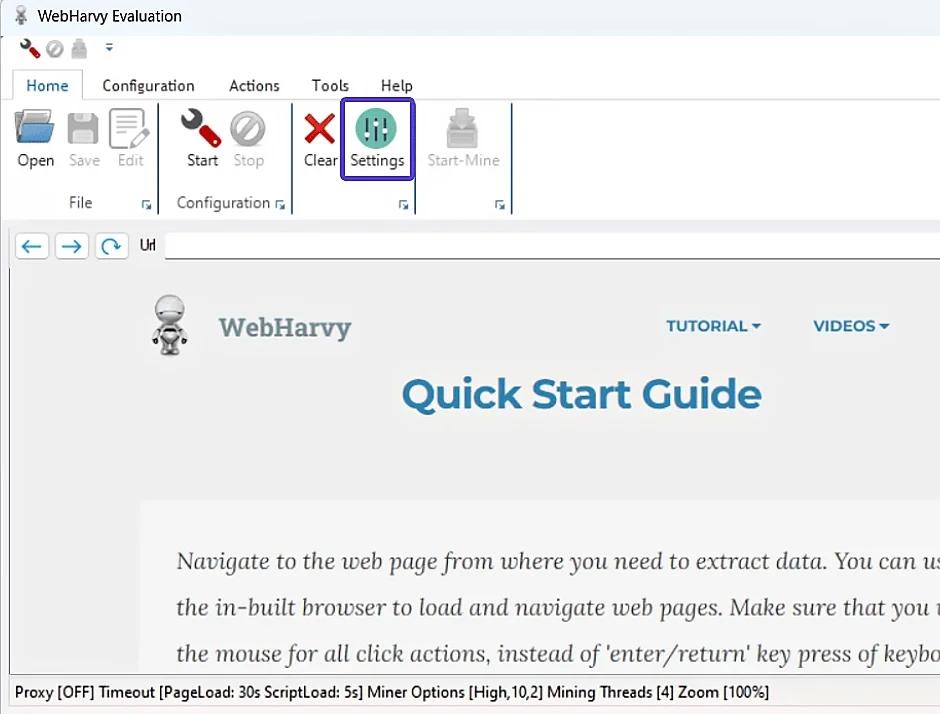
- Aktywuj połączenie przez serwer proxy, wybierając odpowiednią opcję. Typ połączenia powinien być HTTP.
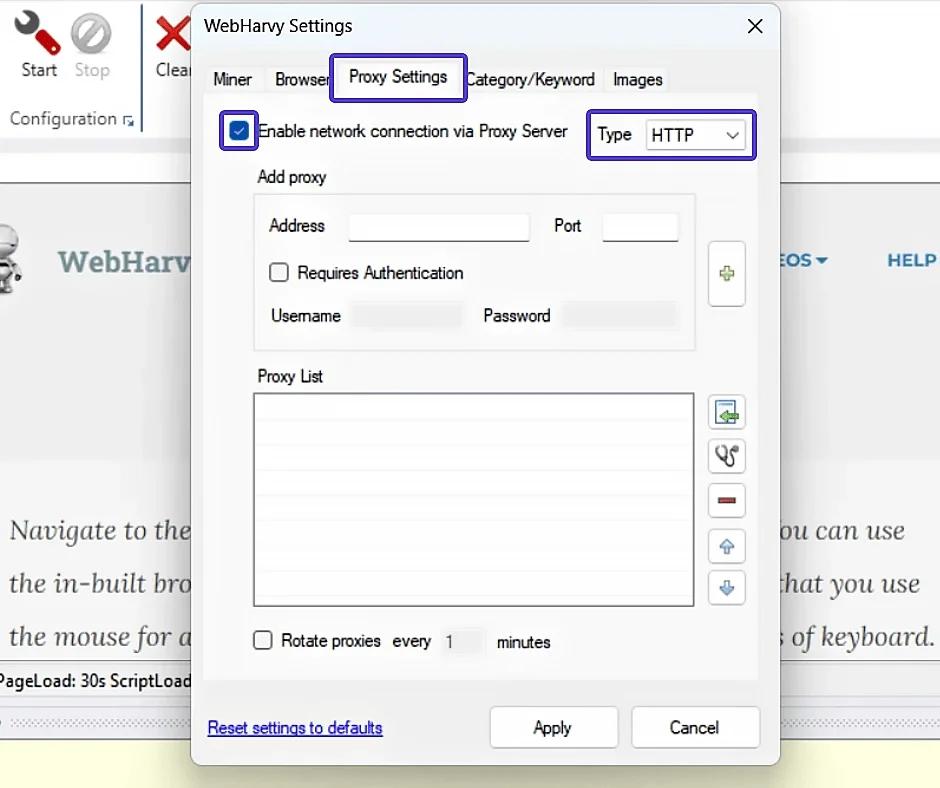
- Wypełnij pola ustawień serwera proxy, opierając się na danych w panelu sterowania.
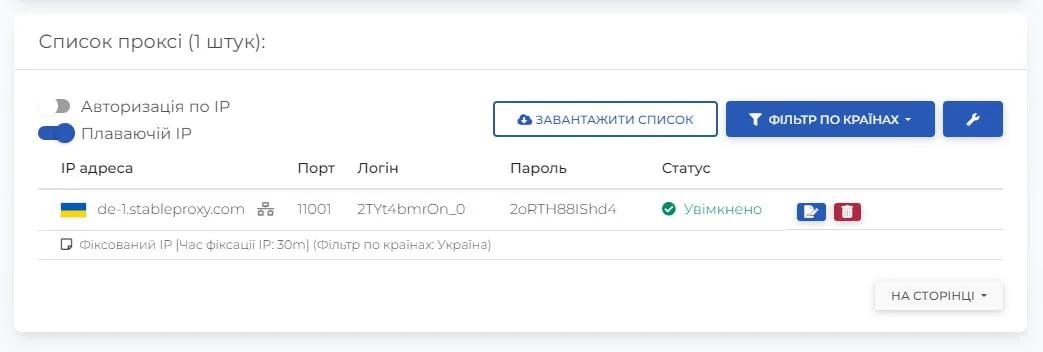
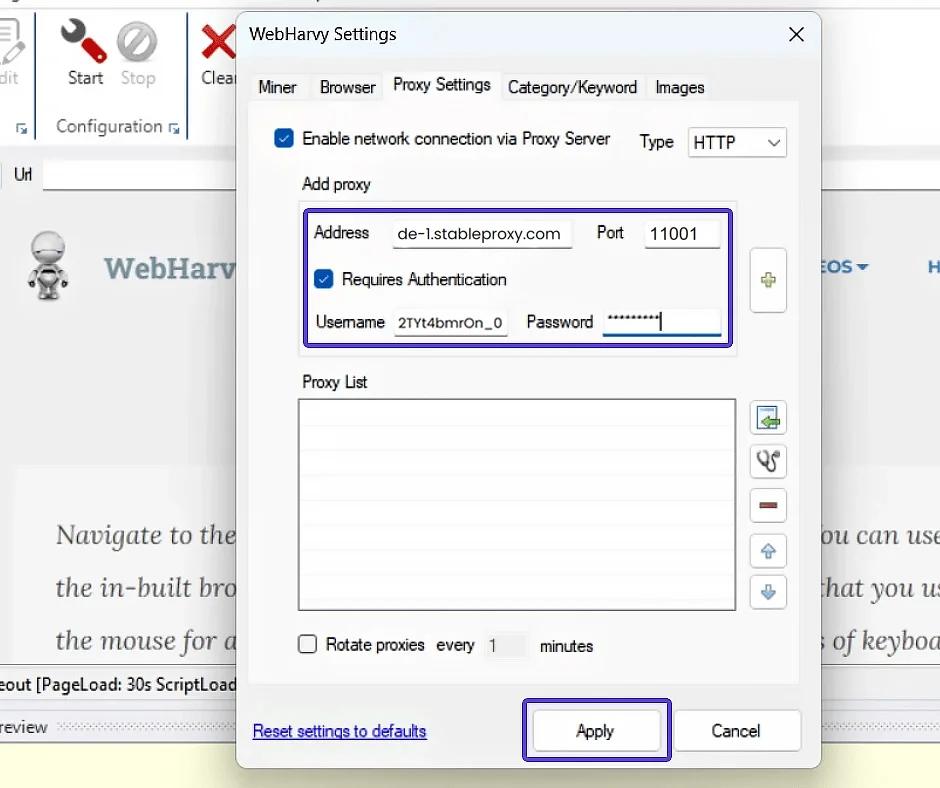
- Włącz uwierzytelnianie, zaznaczając pole "Wymagane uwierzytelnianie". Wklej nazwę użytkownika i hasło podużytkownika Stableproxy. Aby dodać właśnie wprowadzony serwer proxy do listy, kliknij plus. Aby zakończyć proces integracji proxy z WebHarvy, kliknij przycisk Apply.
Teraz WebHarvy z skonfigurowanymi serwerami proxy jest w stanie anonimowo zbierać dane z nieograniczonym dostępem.
Aby wyszukać dane za pomocą WebHarvy, wykonaj proste kroki:
- Otwórz stronę internetową, z której chcesz zebrać dane. Weźmy na przykład https://books.toscrape.com/.
- Aby rozpocząć zbieranie danych, kliknij przycisk Start w WebHarvy.
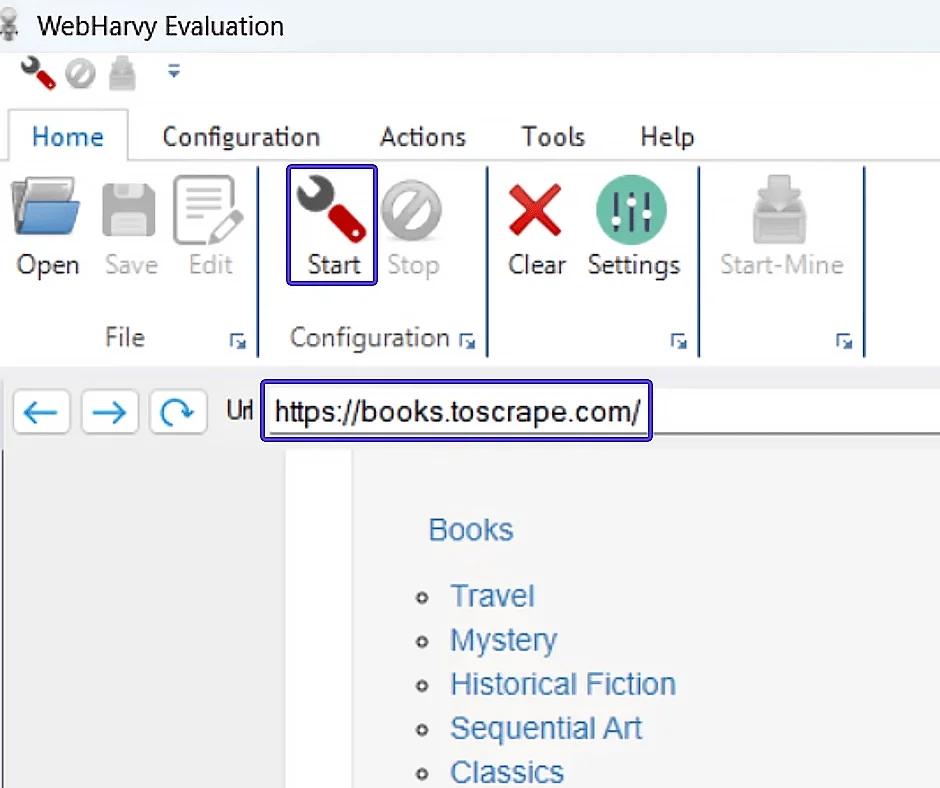
- Określ konkretne atrybuty do wyodrębnienia, takie jak tytuły książek i ich ceny. W WebHarvy, dzięki interaktywnemu interfejsowi, wystarczy kliknąć na potrzebne elementy na stronie, aby je wybrać. Rozpoznawanie wzorców danych na stronie internetowej odbywa się automatycznie, co ułatwia pracę. Jeśli danych jest dużo i są one powtarzane, WebHarvy automatycznie dodaje je do listy do zebrania, nie wymagając dodatkowych działań od użytkownika.
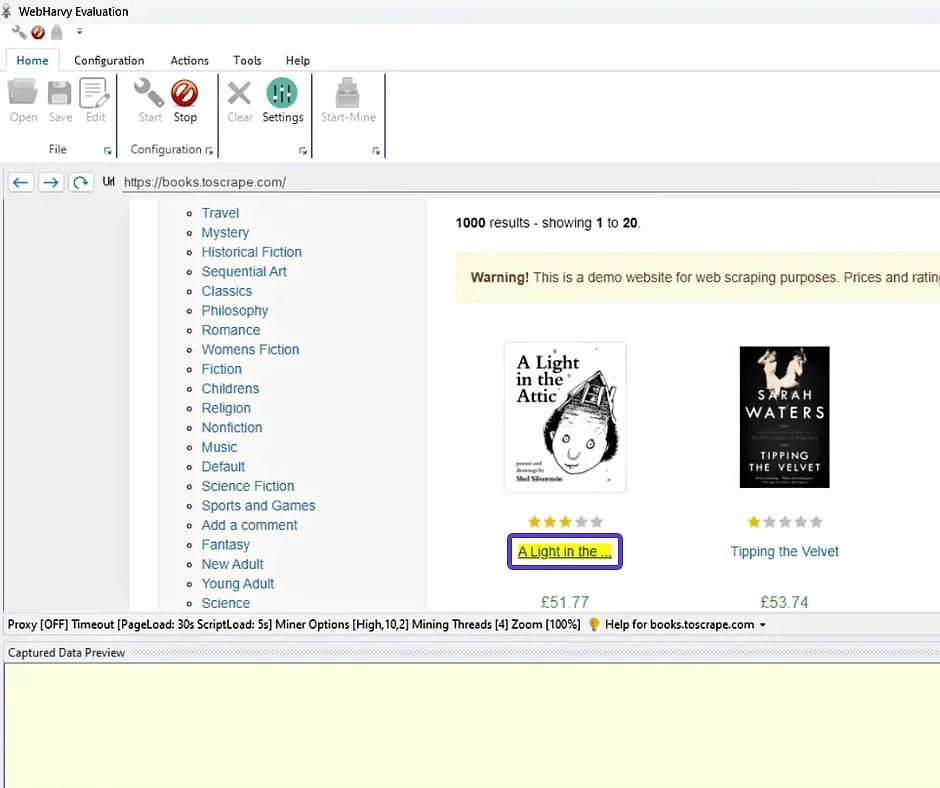
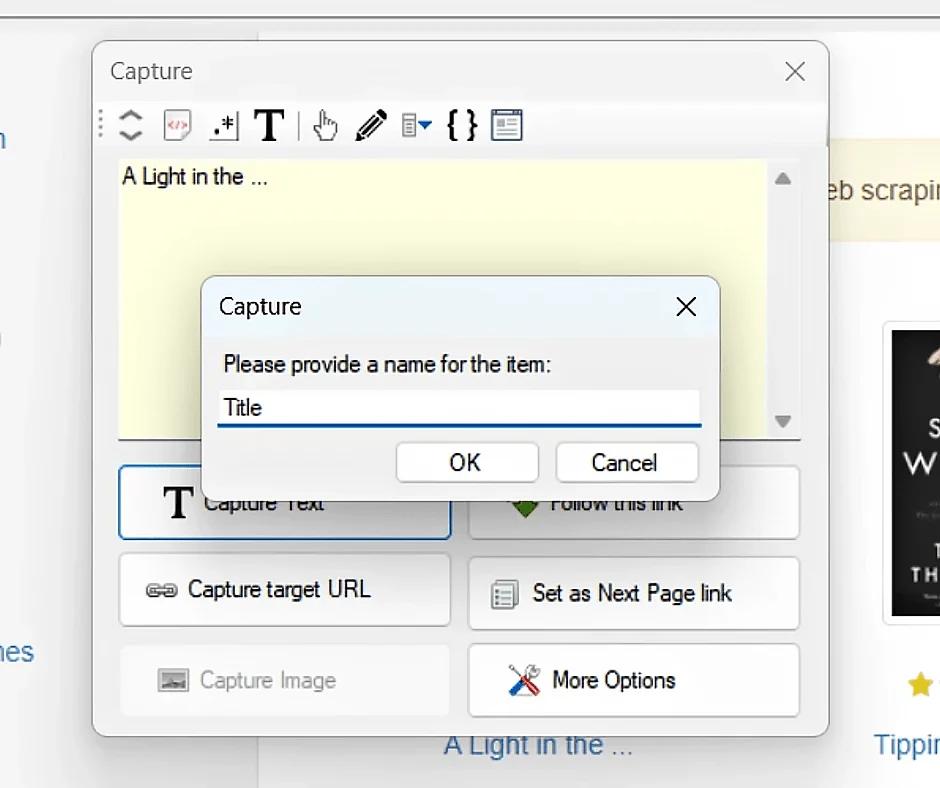
- Wybierz dane, które są potrzebne do wyodrębnienia i dodaj je przez opcję "Capture Text". Nie zapomnij nadać nazwy wybranym elementom.
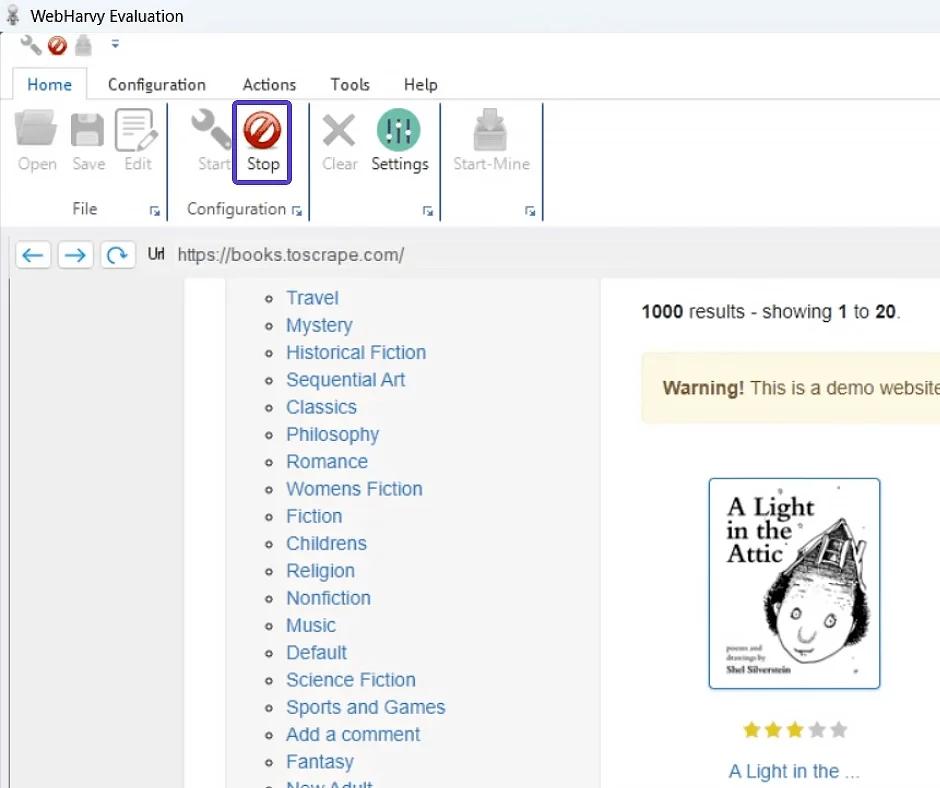
- Po zakończeniu wyboru danych kliknij "Stop", aby zakończyć sesję konfiguracji.
- Aby rozpocząć wyodrębnianie danych, kliknij "Start-Mine", a następnie naciśnij ▶Start.
- Po zakończeniu sesji wyodrębniania danych otwórz "Eksport" i wybierz odpowiedni format eksportu. WebHarvy umożliwia zapisanie zebranych danych w formatach Excel, XML, CSV, JSON i TSV. W razie potrzeby możesz eksportować dane do bazy danych.
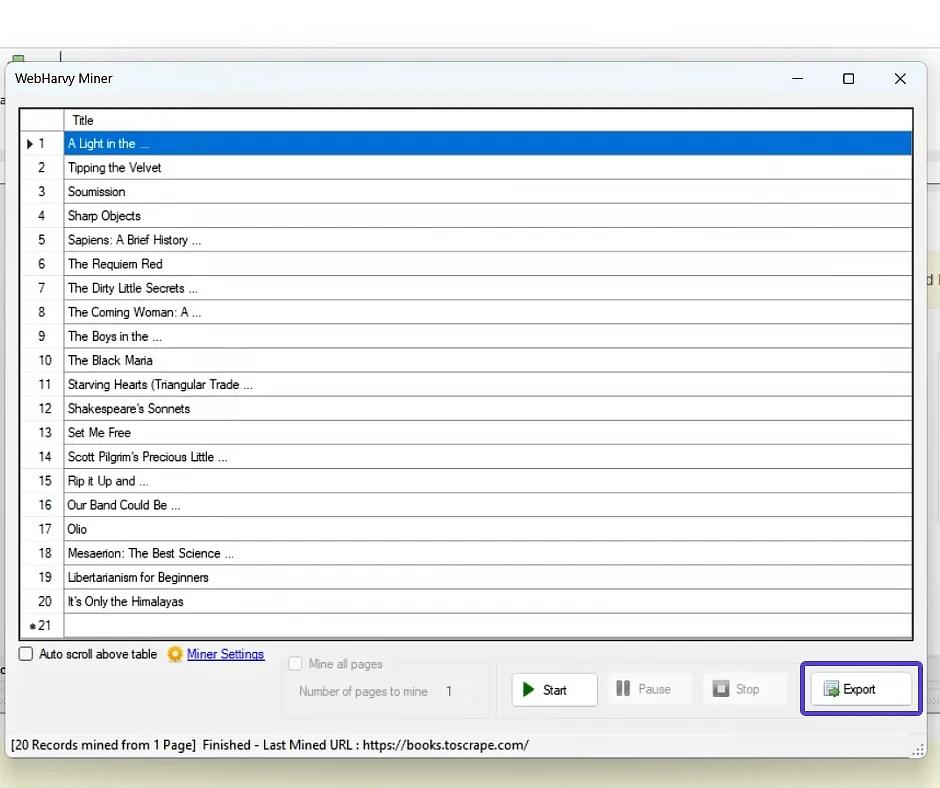
Świetnie! Teraz masz arkusz elektroniczny z tytułami książek i odpowiadającymi im cenami.
StableProxy.pl © 2023-2024